


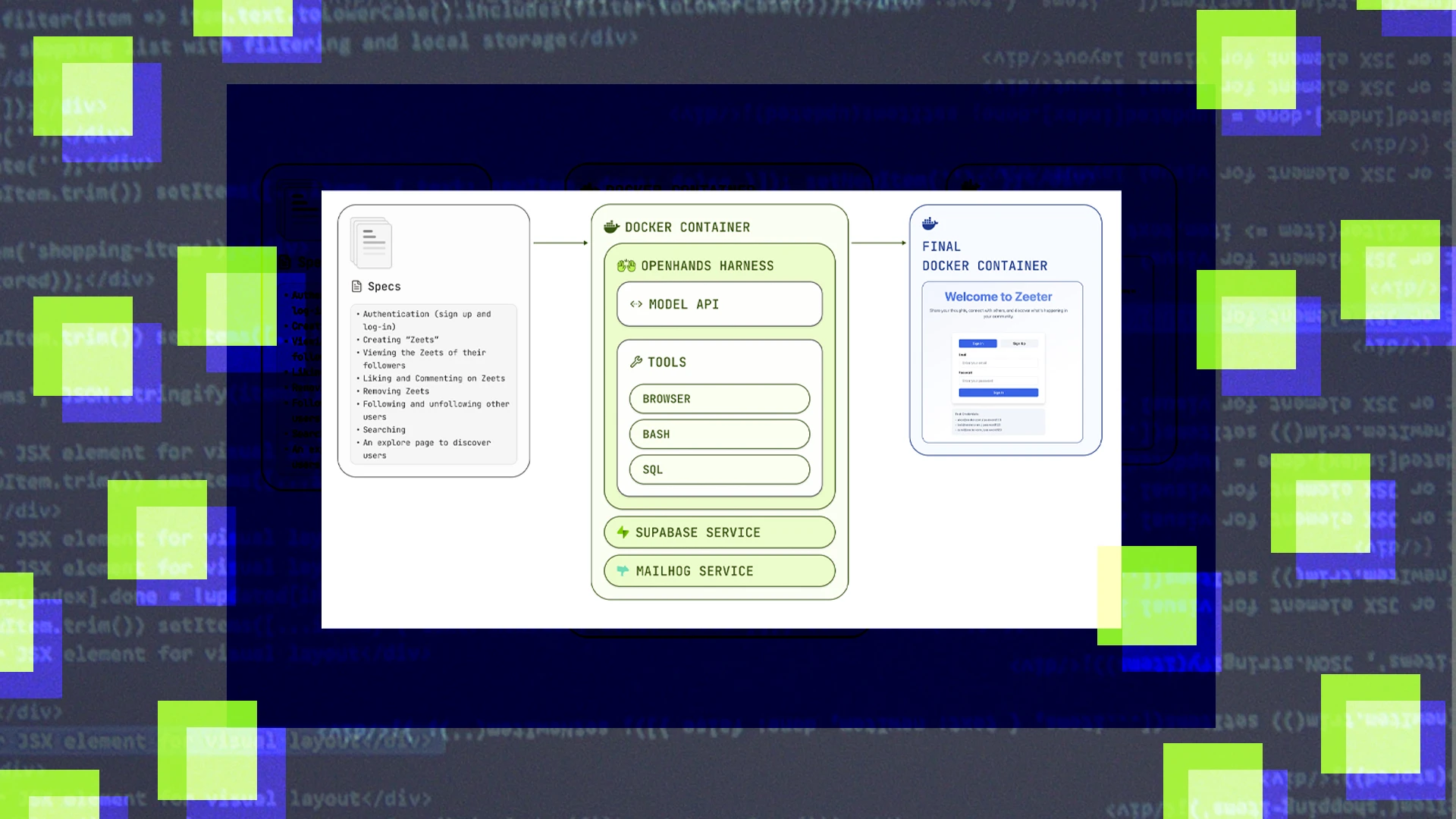





Industry Leaderboard
Updates
benchmark
01/05/26Top performing models from the Vals Index. Includes a range of tasks across finance, coding and law.
All Top Performing Models →Vals Index
1/12/2026
Top performing open weight models from the Vals Index. Includes a range of tasks across finance, coding and law.
All Top Open Weight Models →Vals Index
1/12/2026The top performing models from the Vals Index which are cost efficient.
View full Pareto curve →Vals Index
1/12/2026Model benchmarks are seriously lacking. With Vals AI, we report how language models perform on the industry-specific tasks where they will be used.
By subscribing, I agree to Vals' Privacy Policy.